III.Punica: Multi-Tenant LoRA Serving
SGMV
设计了一个CUDA内核,叫做分段聚合矩阵向量乘法(SGMV) 假设W的形状为[H1, H2],它是预训练模型的权重,LoRA会添加两个小矩阵A形状为[H1, r]和B形状为[r, H2]。在微调模型上运行输入x的过程为y := x @ (W + A@B),这与y := x@W + x@A@B相同。
当有n个LoRA模型时,会有A1, B1, A2, B2, ..., An, Bn。
- 给定输入批次
X := (x1,x2,...,xn),映射到每个LoRA模型,输出为Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn)。 - 左侧部分
X@W就是基础输出部分,因为批处理所以很低延迟 - 右侧使用我们找到的SGMV方法。
批处理效应
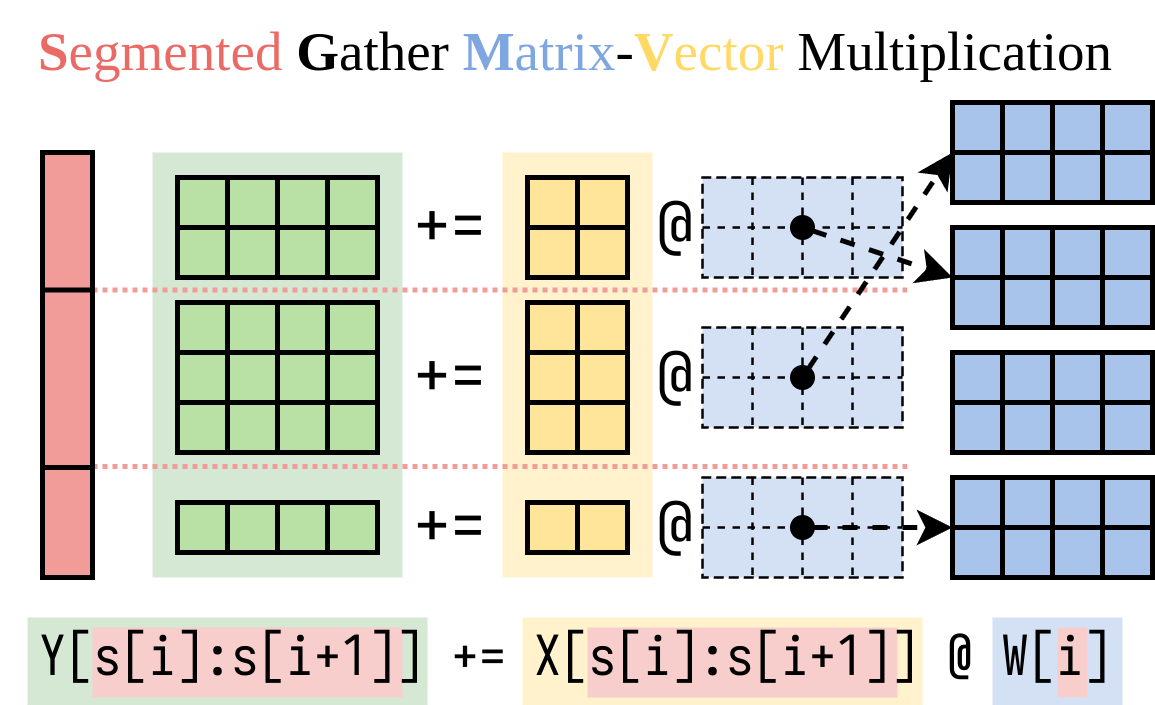
Punica 的 SGMV 公式:
LoRA 权重指的是 LoRA adapter 里面的可训练矩阵 A 和 B 在 Python/PyTorch 里面:
X[0:3]表示取第 0,1,2 行,不包含第 3 行。 所以整个公式其实就是把Y分段拆开,后面整个batch合而为一,通过segment数组进行拆分,不同的使用不同的LoRA 权重矩阵,就划分到不同的组里面然后分组计算后分组叠加:
token index: 0 1 2 3 4 5 6
LoRA id: 2 2 2 5 5 1 1对应的边界数组是:
s = [0, 3, 5, 7]问题: 现在我理解这个机制了,所以虚线箭头表示指针,这些权重全部存在权重池里,每次通过指针去取用。那么节省在哪了,这难道只有一个指针方法吗
代码
在sglang仓库中,
python/sglang/srt/lora/triton_ops/sgemm_lora_b.py就是最简单的升维矩阵算子实现,chunk方法是根据一个 batch 中的 token 数量,用启发式方法决定 chunk size。
_determine_chunk_size调用_determine_chunk_size_for_tokens,根据token数量直接决定chunk的大小- 区别在于chunked的方法中每个segment都规范化为同样chunk大小了,相当于逐chunk选择LoRA adapter以及加载矩阵。
- 具体做法是
prepare_lora_batch中先把 token 按 adapter 重排,再把重排后的 token 流切成固定大小的 chunk。每个 chunk 都会变成一个逻辑上的 "segment",供 chunked_sgmv_* kernel 消费。
SGMV 公式在代码中的体现为
i是当前segment_id,也就是
batch_id = tl.program_id(axis=1)weight_indices是“当前每个 segment 对应哪个 LoRA adapter”的索引表。相当于数组地址指针,偏移起始量。传入的W矩阵流程如下
# 用 `w_index` 选中当前 segment 的 LoRA-B
w_index = tl.load(weight_indices + batch_id)
#构造地址矩阵
w_ptrs = (weights + w_index * w_stride_0) + ( # 跳过前面 `w_index` 个 adapter,来到i对应的LoRA-B
#`n_offset[None, :]` 是输出列方向
#`k_offset[:, None]` 是 rank 方向
k_offset[:, None] * w_stride_2 + n_offset[None, :] * w_stride_1 #广播之后得到 `[BLOCK_K, BLOCK_N]` 地址矩阵
)
#`tl.load(w_ptrs)` 才是真正加载数据
w_tile = tl.load(
w_ptrs, #通过地址加载
mask=(k_offset[:, None] < K - k * BLOCK_K) & n_mask,
other=0.0,
)- 类似的,加载X矩阵的位置是这样吗?
#通过seg长度读取s[i]的实际位置
seg_len = tl.load(seg_lens + batch_id)
if seg_len == 0:
return
seg_start = tl.load(seg_indptr + batch_id)
#获取偏移
s_physical = _resolve_token_positions( #通过 `_resolve_token_positions` 映射成真实 token 行 `s_physical`
sorted_token_ids, seg_start, s_offset, seg_len, SORTED_BY_ADAPTER
)
x_ptrs = x + (s_physical[:, None] * x_stride_0 + k_offset[None, :] * x_stride_1)
#实际加载数据
x_tile = tl.load(
x_ptrs,
mask=(s_offset[:, None] < seg_len) & (k_offset[None, :] < K - k * BLOCK_K),
other=0.0,
)- 最后是写回的时候还需要这个全局的index,对应写回去全局 output 的对应行
# 计算的时候不需要偏移,因为都限制在一块tile中算了
partial_sum += tl.dot(x_tile, w_tile)
# 但是写回的时候还需要
output_ptr = output + (
s_physical[:, None] * output_stride_0 + n_offset[None, :] * output_stride_1
)